一直以来都觉得爬虫是个很神奇的东西,既然已经学了Python,就准备自己来写写看
要用到的库
1
2
3
| import urllib.request
import urllib.parse
import re
|
在Python3较后的版本里,urllib库被封装在urllib.request,功能基本是类似的。
实现原理
爬虫的根本原理是模拟浏览器的行为,从而获取数据,然而现在web技术发展较快,浏览器也有不同的方法来得到数据,我看了些资料,主要就找到两种较常见的方法,一是后端静态加载的网页,通过获取其html源码来得到数据,二是利用JS异步请求动态加载的,通过请求得到JSON数据。
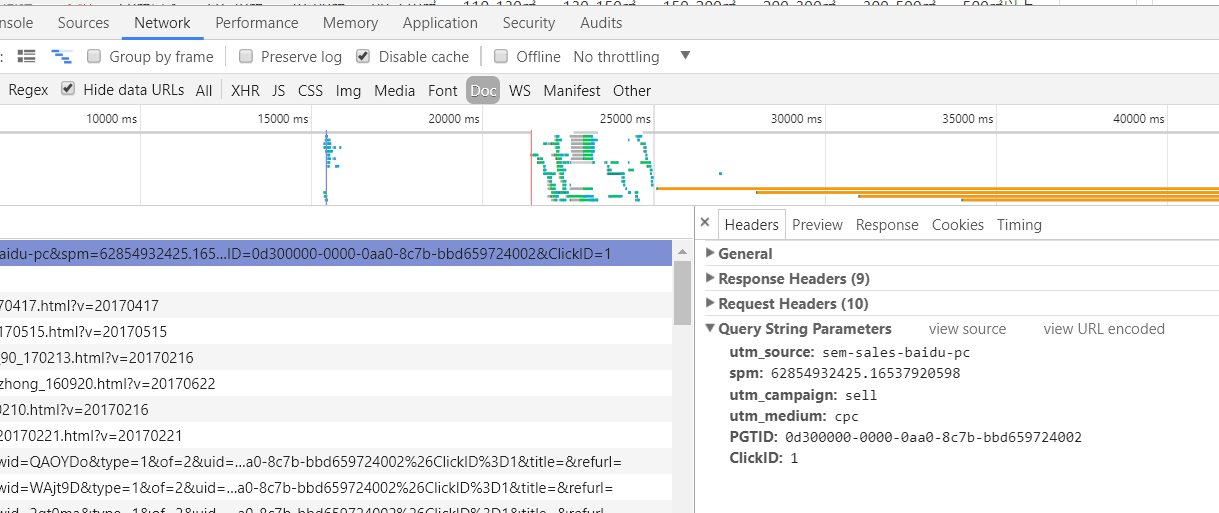
我首先试着获取静态加载的网页,在这里选择了58同城的二手房页面。可以在chrom浏览器开发者工具(F12)的network里看到网址信息
浏览器信息
模拟浏览器的所需的信息在Request Hearders(作为请求头)和Query String Parameters(作为请求发送的数据)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # url地址,这里选择了江干区二手房的第三页,不过其后天数据有随机性,并不固定
url='http://hz.58.com/jianggan/ershoufang/pn3/?'
data={}
head={}
# 请求头
head['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'
# 请求数据
data['utm_source']='sem-sales-baidu-pc'
data['utm_campaign']='sell'
data['utm_medium']='cpc'
data['spm']='62854932425.16537920598'
data['PGTID']='0d300000-0000-0a0c-8067-a60b6ee48510'
data['ClickID']=1
data=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url,data,head,method='GET')
# 将请求得到的响应(response)下载下来
req = urllib.request.urlopen(req)
my_data = req.read()
|
在获得了html源码数据后,如何提取所需的内容,通常是利用正则表达式,这对于没认真学正则的我来说还是挺头疼的,主要是要提取标签内的数据,同时对于byte,str,list,obj,dict等数据结构要会转换运用,才能得到想要的内容。
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import urllib.request
import urllib.parse
import re
#保存HTML源码
def saveFile(data):
path = "D:\\python\\Spider\\58\\html.out"
f = open(path,'wb')
f.write(data)
f.close()
#所需要的数据,考虑到正则匹配的水平太差,就挑了好拿的部分
content = {}
content['tingshi'] = []
content['daxiao'] = []
content['chaoxiang'] = []
content['louceng'] = []
content['jiedao'] = []
content['price'] = []
name = ['tingshi','daxiao','chaoxiang','louceng','jiedao']
#正则匹配式
res_tr1 = r"<ul class='house-list-wrap'>(.*?)</ul>"
res_tr2 = r"<span>(.*?)</span>"
res_price = r'<b>(.*?)</b>'
res_jiedao = r'<a>(.*?)</a>'
def getdata(datalist):
num = -1
for x in datalist:
num = num + 1
num = num%6;
if num == 5:
continue
if num < 4:
print(x)
content[name[num]].append(x)
if num == 4:
content[name[num]].append(re.findall(res_jiedao,x,re.S|re.M))
url='http://hz.58.com/jianggan/ershoufang/pn3/?'
data={}
head={}
head['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'
data['utm_source']='sem-sales-baidu-pc'
data['utm_campaign']='sell'
data['utm_medium']='cpc'
data['spm']='62854932425.16537920598'
data['PGTID']='0d300000-0000-0a0c-8067-a60b6ee48510'
data['ClickID']=1
data=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url,data,head,method='GET')
req = urllib.request.urlopen(req)
my_data = req.read()
saveFile(my_data)
#匹配出ul标签内数据
my_strdata = bytes.decode(my_data)
m_list1 = re.findall(res_tr1,my_strdata,re.S|re.M)
m_tr1 = "".join(m_list1)
content['price'] = re.findall(res_price,m_tr1,re.S|re.M)
m_list2 = re.findall(res_tr2,m_tr1,re.S|re.M)
getdata(m_list2)
print(content)
|
html源码
提取逐个数据
在实际操作中,还是出现了一些状况,对于ul标签内的每一份二手房数据,部分会缺失一部分信息(如建造时间,地铁距离未标明),在提取的时候还是会导致出错,由于该网站后台提供数据是有一定随机性的,尝试几次后,有时能完整提取,有时候就会因为数据的不完整性,导致爬取格式出错。